

過去のWebサイトを調査したいとき、非営利組織「インターネットアーカイブ」が提供する「Wayback Machine」は、SEOの手法として重要な役割を果たします。
Wayback Machineは、以前に公開されていたWebページのデータを完全に保存しており、失われたリンクや削除されたWebサイトにも無料でアクセスできます。
自社や競合他社など、さまざまなビジネスサイトの歴史をチェックし、サイト改善の参考に活用できます。
この記事では、Wayback Machineの基本情報や操作方法、おすすめのWebアーカイブサービス6つについて紹介します。
インターネットアーカイブとは?
インターネットアーカイブ(Internet Archive)は、オンライン上で過去のWebコンテンツやデジタルメディアを保存・アーカイブする非営利組織です。ウェブ上の情報やコンテンツが失われることなく、後世に残るように努力しています。
具体的には、以下のような役割や活動を担っています。
- 図書館の役割: インターネットアーカイブは、デジタル図書館としての側面も持ちます。数百万冊以上の書籍やテキスト、音楽、映画、アート作品などをデジタルフォーマットで保存し、無料で提供しています。
- デジタルアーカイブの保存: インターネットアーカイブは、ウェブサイト、ビデオ、音声、画像、書籍など、デジタルコンテンツ全般を収集・アーカイブし、将来の世代にデジタル遺産を提供することを目指しています。
- 教育と研究: 学校、大学、研究機関などでの教育と研究を支援するため、多くのデジタルコンテンツを提供しています。学生や研究者は過去の情報や資料にアクセスし、知識の共有と発展に貢献できます。
インターネットアーカイブは、デジタル情報の長期保存とアクセス可能性の向上に貢献しており、インターネット上の文化的遺産の保存に寄与しています。
SEOの戦略におけるWayback Machine活用法

Webページのデザインの変更やその時期の確認
Wayback Machineを使用することで、ウェブサイトの過去のバージョンを確認し、デザインの変更やその時期を特定できます。新しいデザインが導入された後のトラフィックや検索エンジンランキングの変化を理解するのに役立ちます。
デザイン変更の影響を評価し、成功した変更を再現するか、問題を特定して修正するのに役立ちます。
URL構成の変更の確認
ウェブサイトのURL構成が変更された場合、SEOに影響を与える可能性があります。
Wayback Machineを使用して、過去のURL構成と現在のURL構成を比較し、変更点を特定できます。
これにより、正しいリダイレクトを設定したり、古いURLから新しいURLへのリンクを更新したりするのに役立ちます。
URLの変動を検証する
ウェブサイト内の特定のURLが頻繁に変更される場合、検索エンジンのクローラーが正しくインデックスできない可能性があります。
Wayback Machineを使用して、特定のURLの過去のバージョンを確認し、変動のパターンを検証できます。これにより、安定したURL構造を確立し、クローラーがコンテンツを正しくインデックスできるようになります。
ソースコードの変動を検証する
ウェブサイトのソースコードが変更されると、SEOに影響を及ぼす可能性があります。Wayback Machineを使用して、過去のソースコードと現在のソースコードを比較し、変動を検証できます。これにより、重要なSEO要因(タグ、マークアップ、スクリプトなど)が変更されていないかを確認し、問題があれば修正できます。
Wayback Machineは、ウェブサイトの歴史的なデータを探求し、SEO戦略の改善に貢献するための貴重なツールです。ウェブサイトの安定性と検索エンジンランキングの向上をサポートするために、積極的に活用しましょう。
Wayback Machineを使った目的別活用法

Webサイトの過去のデータを調べる
Wayback Machineは、ウェブサイトの過去の状態やコンテンツを調査するための貴重なツールです。特定のウェブサイトの過去のバージョンを閲覧し、デザイン、コンテンツ、リンク構造の変化を確認できます。この情報は、ウェブサイトの進化や改善の評価に役立ち、過去の成功体験を活用して将来の戦略を立てるのに役立ちます。
Wayback Machineを使用してウェブサイトの以前のバージョンをチェックする手順は以下の通りです。
例として、ここではAppleについて検索してみます。「Apple Watch (アップル・ウォッチ)」は、2015年4月に初代モデルが発売されました。当時のWEBサイトデザインを見てみましょう。
1.Wayback Machineのウェブサイトにアクセス: ウェブブラウザを開き、Wayback Machineのウェブサイトにアクセスします。
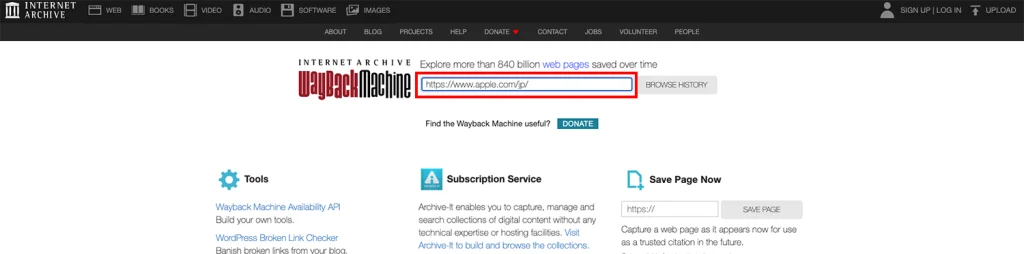
2.ウェブサイトのURL入力: チェックしたい特定のウェブサイトのURLを赤枠に入力してください。
3.カレンダーから日付を選択: ウェブサイトのURLを入力したら、カレンダーが表示されます。カレンダーからウェブサイトの特定の時点を示す日付を選択します。Wayback Machineはその日のウェブサイトのスクリーンショットやデータを提供します。
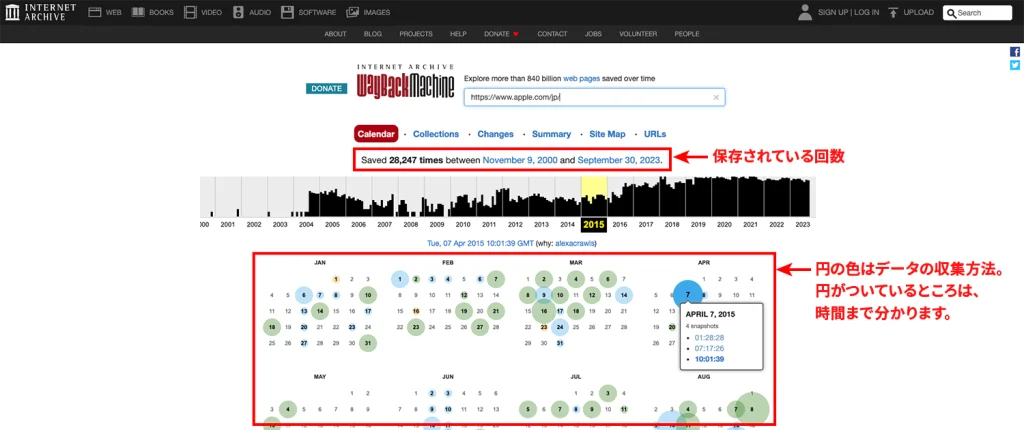
また、Wayback machineでは、保存されているデータの数を確認することもできます。Appleで検索した結果、2000年11月9日から2023年9月30日までに、28,247回データが保存されていることが分かります。
4.選択した日のバージョンを閲覧: 日付を選択したら、その日のウェブサイトのバージョンが表示されます。ウェブページを選択して、選択した日のウェブサイトの以前のバージョンを閲覧します。ページが選択されると、スクリーンショットやテキストコピー、リンクを含む以前のコンテンツが表示されます。
例えば、2015年4月24日に発売を控えた同月の公式サイトは以下のようなデザインでした。
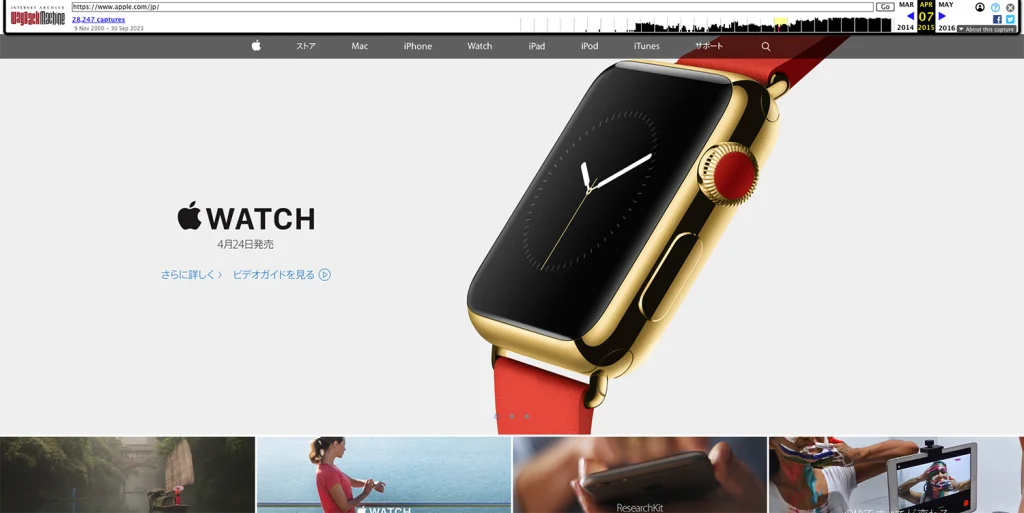
5.データの保存: 必要に応じて、特定の日付のウェブサイトのデータを保存できます。スクリーンショットの保存やテキストのコピーを行い、将来の参照や分析のために保管します。
以上がWayback Machineを使用してウェブサイトの以前のバージョンをチェックする基本的な手順です。この方法を使用して、ウェブサイトの進化や変更履歴を調査し、有用な情報を収集できます。
サイトデータを手動で保管する
Wayback MachineはWebサイトの状態を自動でキャッチしますが、保存のタイミングは不確定です。
そのため、ウェブサイトが更新されるたびに、データが随時保管されているかは保証できませんので、即時データを保存したい場合は、手動保存を推奨します。
以下に、手動でデータを保存する場合の手順を説明します。
- ウェブサイト上の保存したいページのURLをウェブブラウザのアドレスバーに入力します。
- ウェブページが読み込まれたら、画面上部にある「SAVE PAGE」ボタンをクリックします。
- 保存ダイアログボックスが表示されます。ここで、保存先の場所を選択し、保存するファイル名を入力します。
- 必要な設定を行ったら、保存ボタンをクリックします。
- ページの保存が開始され、保存が完了すると画面に「Done!」などのメッセージが表示されます。
保存データの削除方法
Wayback Machineに保存されたデータを削除したい場合、ウェブサイトのオーナーまたは管理者は「Robots.txt」ファイルを使用して特定のページやディレクトリをブロックできます。このファイルをウェブサイトのルートディレクトリに配置し、削除したいコンテンツのパスを指定します。
また、Wayback Machineの運営団体([email protected])に直接問い合わせてデータの削除をリクエストすることも可能です。データの削除は、プライバシーの保護や法的な要件を満たすために重要な手順です。
過去のWebページを探る6つのツール

次に、ウェブサイトの過去データを探せるWebアーカイブサービスを6つピックアップしてみました。
1. Wayback Machine(アメリカ)
「Wayback Machine」は、アメリカの非営利組織「インターネットアーカイブ」が提供する無料のWebアーカイブサービスです。2022年5月時点で、驚異の6,820億ページ以上ものWebページが保管されています。
他のサービスでは手に入らない情報も、Wayback Machineの豊富なデータベースならばアクセス可能であることが強みです。
利用方法: 特定のウェブページのURLを入力すると、過去のバージョンを表示するカレンダーが表示されます。任意の時点を選んでウェブページの以前の状態を閲覧できます。
2. Stanford Web Archive Portal(アメリカ)
スタンフォード大学が提供するWebアーカイブポータルで、学術的なリサーチに役立つウェブコンテンツのアーカイブを提供しています。主に学術的な目的で使用されます。
利用方法: ウェブページのURLやキーワードを検索し、過去のウェブコンテンツを検索します。学術的な研究や調査に適しています。
3.WARP(日本)
国立国会図書館が運営するWARP(Web ARchive Project)は、日本のウェブアーカイブプロジェクトで、日本国内のウェブサイトのアーカイブを提供しています。日本語のウェブコンテンツを調査する際に便利です。
利用方法: WARPのウェブサイトを訪れ、検索バーにキーワードやURLを入力し、過去の日本のウェブページを検索します。
4.Library of Congress(アメリカ)
米国議会図書館が手掛ける「Library of Congress」も、ユニークなWebアーカイブサービスです。
週1回、月1回、四半期に一回等、一定の頻度で1つのウェブサイトの収集を行う点が特徴で、収集から1年後、発信者の許可を得た上で公開されます。少数ながら、日本語サイトの収集も行われています。
利用方法: アメリカ国内のウェブコンテンツのアーカイブを検索し、アメリカ国内の歴史や文化に関する研究に利用できます。
5.UK Web Archive(イギリス)
大英図書館が運営する「UK Web Archive」は、SNSをはじめとした新しいメディアの情報も公的記録として保存しています。
データは英国図書館、英国図書館分館、スコットランド図書館、ウェールズ国立図書館の4つの図書館にバックアップされ、冗長性が保たれているため、データの安全性も高いです。
利用方法: イギリス国内のウェブコンテンツを検索し、イギリスの歴史や文化に関する情報を閲覧できます。
6.ウェブ魚拓(日本)

「ウェブ魚拓」は、株式会社アフィリティーが運営している、手動での保存を特色とするサービスです。
「Wayback Machine」と異なる点は、自動的に保存されるのではなく、ユーザーが自分で保存したいページのURLを入力することで、過去の情報を保存できる点です。
利用方法: ウェブ魚拓のウェブサイトを訪れ、特定のウェブページのURLを入力してその過去のバージョンを
見ることができます。ウェブ魚拓では、過去のウェブページのスクリーンショットを提供し、特定の日本語ウェブコンテンツの変遷を追跡できます。
これらのウェブアーカイブツールは、歴史的なウェブコンテンツの調査や特定の情報の復元に役立ちます。研究、学術的な目的、ウェブサイトの変更履歴の確認、または単に過去のウェブページを閲覧するために利用されています。選択肢に応じて、特定の国や地域のウェブコンテンツにアクセスすることができます。
まとめ

この記事では、さまざまなWebアーカイブサービスをご紹介しました。全て無料で利用可能ですので、SEOの一環として、または研究・調査のためにぜひ役立ててみてください。
適切なアーカイブサービスを活用し、高品質なWebコンテンツを作りましょう。